
Amazon ist ein begehrter Arbeitgeber – das Unternehmen erhält eine Flut von Bewerbungen. Kein Wunder, dass es nach Möglichkeiten sucht, die Vorauswahl zu automatisieren. So entwickelte der Konzern einen Algorithmus, der aus den Bewerbungsunterlagen die vielversprechendsten herausfiltern sollte. Trainiert wurde diese Künstliche Intelligenz (KI) mit den Datensätzen der Beschäftigten, um so zu lernen, wer gut zu Amazon passt. Doch die Software benachteiligte systematisch Frauen. Die Trainingsdaten stammten von sehr viel mehr Männern als Frauen, weil in der Vergangenheit mehr Männer eingestellt worden waren. Der Algorithmus identifizierte deshalb das Geschlecht als K.-o.-Kriterium. Da diese Diskriminierung trotz Anpassungen am Algorithmus nicht verlässlich auszuschließen war, gab Amazon das System schließlich wieder auf.
Das Beispiel zeigt, wie schnell jemand in einer Welt der Algorithmen Nachteile haben kann – ohne zu wissen warum, und oft, ohne es überhaupt zu erfahren. „Passiert das bei automatisierten Musikempfehlungen oder der maschinellen Übersetzung, mag das unkritisch sein“, sagt Marco Huber. „Doch bei juristisch und medizinisch relevanten Fragen oder in sicherheitskritischen industriellen Anwendungen sieht die Sache anders aus.“

Huber ist Professor für Kognitive Produktionssysteme am Institut für Industrielle Fertigung und Fabrikbetrieb (IFF) der Universität Stuttgart und leitet am Fraunhofer-Institut für Produktionstechnik und Automatisierung (IPA) das Zentrum für Cyber Cognitive Intelligence.
Gerade die KI-Verfahren, die eine hohe Prognosequalität erreichen, sind oft auch die, deren Entscheidungsfindung besonders undurchsichtig ist. „Neuronale Netze sind das bekannteste Beispiel“, so Huber. „Sie sind eine Black Box, da Daten, Parameter und Rechenschritte sich nicht mehr nachvollziehen lassen.“ Zum Glück gibt es auch KI-Verfahren, deren Entscheidungen nachvollziehbar sind. Mit ihrer Hilfe versucht Hubers Team nun neuronalen Netzen auf die Schliche zu kommen. Die Black Box soll zur White Box werden.
Mit Ja-Nein-Fragen zur White Box
Ein Ansatz sind Entscheidungsbäume. Entscheidungsbaum-Algorithmen stellen aufeinander aufbauende Ja-Nein-Fragen strukturiert dar. Sogar in der Schule ist man damit in Berührung gekommen: Wer beim mehrfachen Wurf einer Münze alle möglichen Kombinationen aus Kopf und Zahl grafisch darstellen musste, hat einen Entscheidungsbaum gezeichnet. Die Entscheidungsbäume, die Hubers Team nutzt, sind natürlich komplexer.
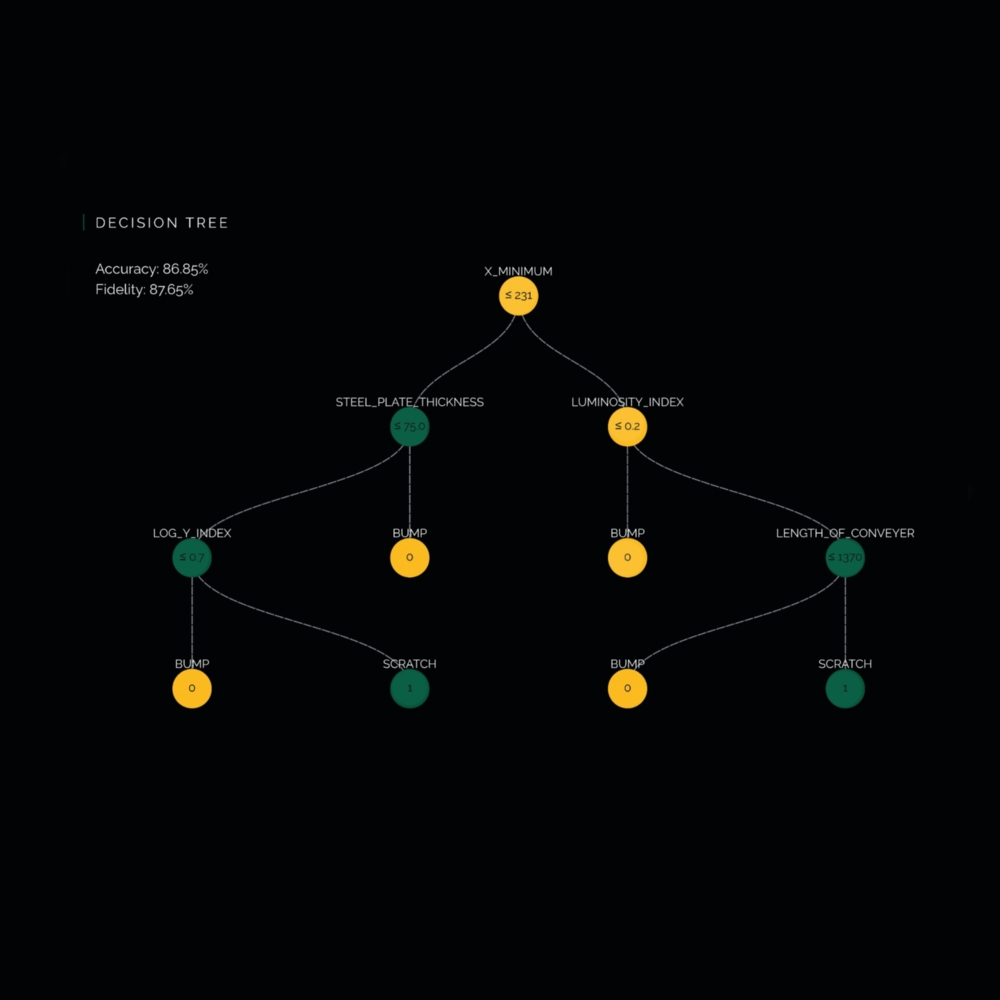
„Neuronale Netze müssen mit Daten trainiert werden, damit sie überhaupt vernünftige Lösungen liefern“, erklärt er den Ansatz. Eine Lösung bedeutet in diesem Fall, dass das Netz aussagekräftige Prognosen trifft. Das Training stellt ein Optimierungsproblem dar, das zu unterschiedlichen Lösungen führen kann. Diese hängen neben den verwendeten Daten auch von Randbedingungen ab – hier kommen die Entscheidungsbäume ins Spiel. „Wir führen eine mathematische Randbedingung in das Training ein, sodass sich ein möglichst kleiner Entscheidungsbaum aus dem neuronalen Netz extrahieren lässt“, sagt Huber. Und weil der Entscheidungsbaum die Prognosen nachvollziehbar macht, wird das Netz zur White Box. „Wir drängen es dazu, unter den vielen möglichen Lösungen eine spezifische anzunehmen,“ sagt der Informatiker. „Vermutlich ist es nicht die optimale Lösung, aber dafür eine nachvollziehbare.“
Neuronale Netze
Neuronale Netze in der KI sind dem menschlichen Gehirn nachempfunden. Die künstlichen Neuronen können Informationen erhalten und verarbeiten sowie untereinander kommunizieren.
Die kontrafaktische Erklärung
Es gibt weitere Verfahren, um Entscheidungen von neuronalen Netzen nachvollziehbar zu machen. „Eines, das in seiner Aussage für Laien leichter verständlich ist als ein Entscheidungsbaum, ist die kontrafaktische Erklärung“, sagt Huber. Er gibt ein Beispiel: Wenn eine Bank auf Basis eines Algorithmus einen Kredit ablehnt, könnte der Betroffene die Gegenfrage stellen, was sich an den Antragsdaten ändern müsste, damit der Kredit genehmigt würde. Dann wäre rasch klar, ob jemand systematisch benachteiligt wurde oder die Kreditwürdigkeit tatsächlich nicht mehr zuließ.
So eine kontrafaktische Erklärung dürfte sich dieses Jahr auch mancher Jugendliche in Großbritannien gewünscht haben. Infolge der Corona-Pandemie fielen die Abschlussprüfungen aus. Das Bildungsministerium beschloss daraufhin, die Abschlussnoten per Algorithmus zu erzeugen. Das Ergebnis: Schülerinnen und Schüler hatten Noten, die teils deutlich unter den zu erwartenden Leistungen lagen. Ein Aufschrei ging durchs Land. Zwei wesentliche Aspekte waren in den Algorithmus eingeflossen: die Einschätzung der individuellen Leistung und die Prüfungsleistungen an der jeweiligen Schule aus den Vorjahren. Der Algorithmus verstärkte dadurch bestehende Ungleichheiten: Eine begabte Schülerin schnitt in einer Brennpunktschule automatisch schlechter ab als an einer renommierten Schule.

Risiken und Nebenwirkungen aufzeigen
Für Sarah Oppold ist dies ein Beispiel für einen unzureichend umgesetzten Algorithmus. „Die Daten waren ungeeignet und das zu lösende Problem war schlecht formuliert“, bemängelt die Informatikerin, die am Institut für Parallele und Verteilte Systeme (IPVS) der Universität Stuttgart promoviert. Sie forscht zu der Frage, wie sich KI-Algorithmen bestmöglich und transparent gestalten lassen. „Viele Forschungsgruppen konzentrieren sich dabei primär auf das Modell, das dem Algorithmus zugrunde liegt“, sagt Oppold. „Wir versuchen die gesamte Kette abzudecken, von der Erhebung und Vorverarbeitung der Daten über die Entwicklung und Parametrisierung der KI-Methode bis zur Visualisierung der Ergebnisse.“ Das Ziel ist in diesem Fall also keine White Box für einzelne KI-Methoden, sondern den ganzen Lebenszyklus des Algorithmus transparent und nachvollziehbar darzustellen.
Entstanden ist dazu ein Frameworks, eine Art Ordnungsrahmen. So wie bei einem Digitalbild Metadaten wie Belichtungszeit, Kameratyp und Aufnahmeort hinterlegt sind, so wären zu einem Algorithmus mittels des Framework Erklärungen hinterlegt – etwa, dass die Trainingsdaten sich auf Deutschland beziehen und daher die Ergebnisse nicht auf andere Länder übertragbar sind. „Man kann es sich wie bei einem Medikament vorstellen“, sagt Oppold. „Es gibt eine medizinische Indikation, es gibt eine Dosierung, es gibt Risiken und Nebenwirkungen. Auf dieser Grundlage entscheidet der Arzt oder die Ärztin, für welche Patienten sich das Medikament eignet.“
Noch ist das Framework nicht so weit entwickelt, dass es Vergleichbares für einen Algorithmus leistet. „Derzeit berücksichtigt es nur tabellarische Daten“, so Oppold. „Wir wollen es nun auf Bild- und Streamingdaten erweitern.“ Zudem müsste in ein praktisch einsetzbares Framework interdisziplinäre Expertise einfließen – etwa von KI-Entwicklern, aus den Sozialwissenschaften und von Juristen. „Ab einer gewissen Reife des Frameworks“, sagt die Informatikerin, „sind Kooperationen mit der Industrie sinnvoll, um es weiterzuentwickeln und industriell eingesetzte Algorithmen transparenter zu machen.“
Text: Michael Vogel
Prof. Marco Huber, Institut für Industrielle Fertigung und Fabrikbetrieb
E-Mail
Tel.: 0711 685-61888
Sarah Oppold, Institut für Parallele und Verteilte Systeme
E-Mail
Tel.: 0711 685-88255