Bei Experimenten zur Katalyse entstehen – wie in anderen Wissenschaftsbereichen auch – große und komplexe Datenmengen, deren Auswertung und Wiederverwendung eine enorme Herausforderung darstellt. Ein Team unter der Leitung von Prof. Jürgen Pleiss vom Institut für Biochemie und Technische Biochemie der Universität Stuttgart stellt jetzt in der Fachzeitschrift "Nature Methods" ein Datenaustauschformat vor, das die Ergebnisse enzymatischer Experimente komplett erfasst, die Daten strukturiert ablegt und nachvollziehbar macht.
Während in der Forschung weltweit immer mehr Daten generiert werden, sind diese Datenmengen durch die derzeitige Praxis der Vermittlung wissenschaftlicher Ergebnisse kaum noch zu bewältigen. Schon die manuelle Verwaltung der eigenen Daten ist zeitaufwändig und fehleranfällig, und der Zugriff auf und die erneute Analyse von Daten anderer Forschungsgruppen erweist sich als nahezu unmöglich. Fehlende Standards, unvollständige Metadaten und fehlende Originaldaten machen es fast unmöglich, publizierte Ergebnisse zu reproduzieren. Immer mehr Forschende fühlen sich, als würden sie in einem Datentsunami ertrinken.
Dies gilt auch für Studien zur katalytischen Aktivität, Selektivität und Stabilität von Enzymen und enzymatischen Netzwerken, einem Forschungsfeld, das für die industrielle Biotechnologie ebenso von großer Bedeutung ist wie für biomedizinische Fragestellungen. Erschwerend kommt in diesem Bereich hinzu, dass Daten zur Beschreibung enzymatischer Experimente besonders komplex sind. Denn eine enzymatische Reaktion hängt von vielen Faktoren ab wie der Proteinsequenz des Enzyms, dem rekombinanten Wirtsorganismus, den Reaktionsbedingungen und von nicht-enzymatischen Nebenreaktionen. Außerdem beeinflussen weitere Effekte wie Inaktivierung oder Hemmung des Enzyms oder die Verdunstung des Mediums das Ergebnis.
Nahtloser Kommunikationskanal
Hoffnung macht nun das neuartige, standardisierte Datenaustauschformat „EnzymeML“, das 23 Autoren*innen aus 14 verschiedenen Forschungseinrichtungen in der Fachzeitschrift „Nature Methods“ vorstellen*. EnzymeML kann die Ergebnisse eines enzymatischen Experiments komplett erfassen, von den Reaktionsbedingungen über die gemessenen Daten bis zu dem zur Analyse experimenteller Daten verwendeten kinetischen Modell und den geschätzten kinetischen Parametern. Das Format bietet somit einen nahtlosen Kommunikationskanal zwischen experimentellen Plattformen, elektronischen Laborbüchern, Werkzeugen zur Modellierung der Enzymkinetik, Veröffentlichungsplattformen und enzymatischen Reaktionsdatenbanken. „Wir zeigen die Machbarkeit und Nützlichkeit der EnzymeML-Toolbox mit Hilfe von sechs Szenarien, in denen Daten und Metadaten verschiedener enzymatischer Reaktionen gesammelt, analysiert und zur zukünftigen Wiederverwendung in öffentliche Datenbanken hochgeladen werden“, erklärt Erstautorin Simone Lauterbach.
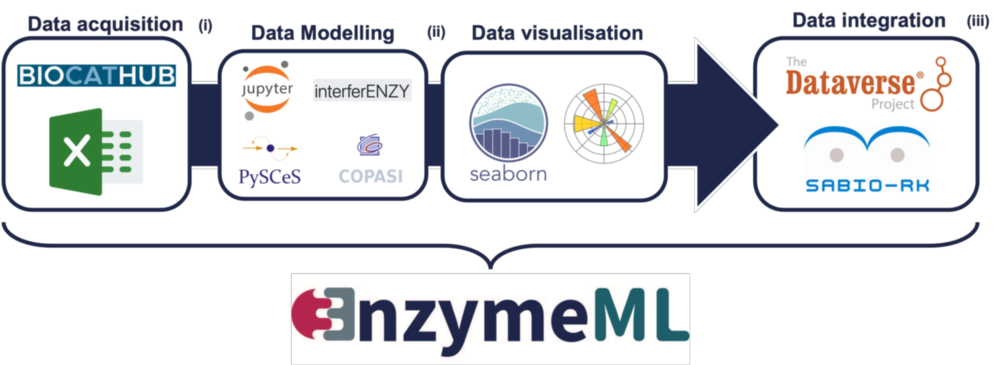
EnzymeML-Dokumente sind strukturiert und standardisiert, sodass die darin codierten experimentellen Ergebnisse zusammenpassen und von anderen Gruppen genutzt werden können. Da ein EnzymeML-Dokument maschinenlesbar ist, kann es in einem automatisierten Arbeitsablauf zur Speicherung, Visualisierung, Datenanalyse und erneuten Analyse zuvor veröffentlichter Daten verwendet werden, ohne Einschränkungen hinsichtlich der Größe jedes Datensatzes oder der Anzahl der Experimente.
„Die Digitalisierung der Biokatalyse steigert die Effizienz bei der Verwaltung, Visualisierung und Analyse von Daten“, betont Prof. Jürgen Pleiss, korrespondierender Autor und Koordinator des Projekts. Zudem verbessere die Digitalisierung die Reproduzierbarkeit von Experimenten und Datenanalysen und fördere damit das Vertrauen in die Wissenschaft. „Die EnzymeML-Toolbox nutzt die schnell wachsenden enzymatischen Daten optimal aus und ist ein nützliches Instrument, das es Forschenden ermöglicht, auf der Forschungsdatenwelle zu surfen.“
EnzymeML fließt in die Arbeit des Sonderforschungsbereichs „Molekulare heterogene Katalyse in definierten, dirigierenden Geometrien (SBF 1333) sowie in das Exzellenzcluster „Datenintegrierte Simulationswissenschaft“ (SimTech) an der Universität Stuttgart ein und ist zudem in die Nationalen Forschungsdateninfrastrukturen NFDI4Cat und NFDI4Chem eingebunden.
Fachlicher Kontakt:
Prof. Dr. Jürgen Pleiss, Universität Stuttgart, Institut für Biochemie und Technische Biochemie, Tel.: +49 711 685 63191, E-Mail
Originalpublikation:
Simone Lauterbach, et al.: EnzymeML: seamless data flow and modeling of enzymatic data", Nature Methods 2023, DOI 10.1038/s41592-022-01763-1